Son yıllarda dijitalleşen dünyanın sonucunda ortaya çıkan dijital uygulamalar birbirinden farklı veriler ortaya çıkardı. Ortaya çıkan bu verileri işleyebilmekse eskisine göre çok daha önemli hale geldi. Dijitalleşme döneminden önce, birçok kurumsal yazılım firması kendi çalışanlarının operasyonel işlerini takip edebilmek amacıyla oluşturduğu finans, satış, müşteri verileri gibi verilerin işlenmesine odaklıydı. Günümüzdeyse firmaların ürün ve servislerini kullanan kullanıcıların çok daha büyük hızlarla oluşturduğu verileri işlemek daha önemli hale geldi. Böylelikle müşterilere daha iyi hizmet sunmak ve ürün çeşitliliğini takip etmek açısından daha sağlıklı veriler elde edilebildi. Ayrıca gelişen yazılım teknolojileri, bulut çözümleri gibi alt yapısal parametreler de verilerin işlenmesinin çeşitliliğini artırmış durumda. Daha önceden yapısal bir veri tabanı yeterli olurken, bu dönemde yapısal olmayan verilerin işlenmesi ve anlamlandırılması için kullanılan araçlar ve çeşitlilikleri de gelişti. Dolayısıyla veri işlemek deyince akla gelen veri tabanı, veri işleme ve dönüştürme gibi araçların dışına çıkılarak Python gibi açık kodlu araçlar veri işlemede sıkça kullanılır oldu.
Bu yazımızda Python’un veri işleme kütüphanesi olan pandas’ın temel fonksiyonlarına değinerek veri işlemeye giriş yapacağız.
Python kodunuzda “pandas” kütüphanesini öncelikle içe aktarmanız gerekir. Bunun için kabul edilen standart aşağıdaki şekildedir. Farklı kişilerin kodunuzu rahatlıkla anlaması için bu şekilde kullanılması önerilir;
import pandas as pd
Kütüphaneyi kodumuzda içeri aldıktan sonra ilk işimiz işleyeceğimiz verilere erişim sağlamaktır. Veriler farklı ortamlarda tutulabileceği için pandas veri erişimine farklı metotlar ile çözüm sunmaktadır:
Buna göre örnek kod şu şekilde olmalıdır. Verilerin bulunduğu dosya isminin “veri.csv” olduğunu kabul edelim.
veri = pd.read_csv(“veri.csv”)
Bu kod ile “veri.csv” dosyası içerisinde bulunan verileri “dataframe” nesnesine yüklemiş oluyoruz. Bundan sonrasında yapılacak olan işlemler bilgisayarın hafızasında yapılacaktır. Dolayısıyla yüklenen verinin büyüklüğünün bilgisayarın hafızasından fazla olmaması ve diğer uygulamaların çalışabileceği kadar yer bulunması gerekir.
Yukarıda anlatılan işlemleri jupyter notebook üzerinden aşağıdaki şekilde deneyebilirsiniz. Veri seti yüklenirse herhangi bir hata almadan sonraki komut satırına geçer.
Bu şekilde veriyi yükledikten sonra ilk iş olarak veriyi inceleyip içerisinde hangi kolonlar olduğunu, bu kolonların hangi veri tipinde olduğunu veya genel basit istatistiklerini incelemek isteyebiliriz. Bunun için de aşağıdaki fonksiyonlar kullanılabilir.
İlk olarak ilk veya son satırları görmek isteyebiliriz. Son satırları istediğimiz verinin tamamının düzgün yüklendiğini kontrol etmek amacıyla kullanılabilir. Bunun için kullanılacak fonksiyonlar head ve tail fonksiyonlarıdır.
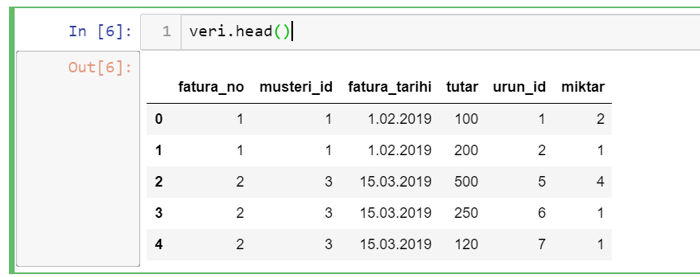
Head ve tail fonksiyonlarına görmek istediğiniz satır sayısını parametre olarak da iletebilirsiniz. Parametre verilmezse sadece 5 satır gösterecektir.
Verinin içerisini gördükten sonra genel olarak veri seti üzerinde özet bilgilere ulaşmak isterseniz info fonksiyonunu kullanabilirsiniz.
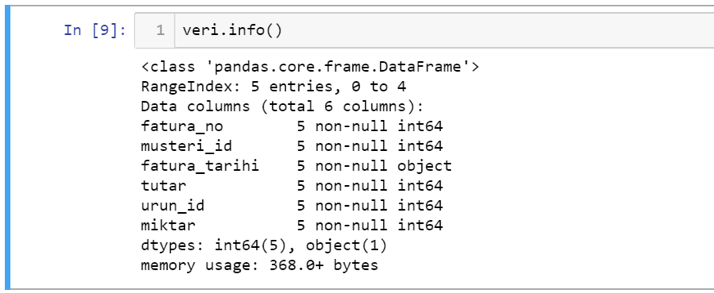
Buna göre fonksiyonun çıktısında verinizdeki kolonların tiplerini, boş olmayan (non-null) kayıt sayısını, hangi veri tipinden kaç kolon olduğunu ve index range’ini özet olarak bir bakışta inceleyebilirsiniz.
Son olarak elinizdeki kolonların basit istatistik dağılımlarını incelemek isterseniz describe fonksiyonu ile bunu yapabilirsiniz. Bu fonksiyon ile de aşağıdaki çıktı oluşacaktır.
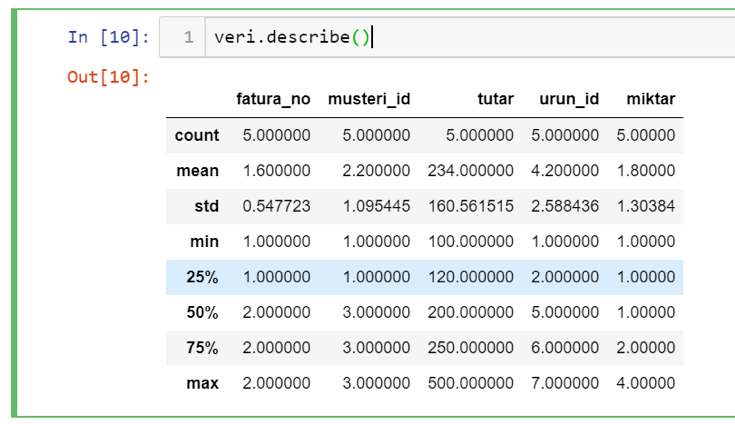
Buna göre verinizdeki kolon setlerinin en küçük, en büyük ve ortalama değerleri ile yüzdelik dilimlere hangi değerler üzerinden ulaşılabildiği izlenebilir. Özellikle ölçüme dayalı alanlar için veri dağılımınızı hızlı bir şekilde incelemek açısından oldukça kullanışlı bir fonksiyondur.
Bu yazımızda basitçe bir veri seti nasıl yüklenir ve nasıl tanınır onu anlatmaya çalıştım. Daha sonraki yazılarımda veri setleri ile yapılabilecek diğer işlemlere de devam edeceğiz.
Kaynak dosyalara buradan erişebilirsiniz.
makale ve bilginiz için teşekkürler.
Bilgi için teşekkürler. Bu yazılar sayesinde kendimizi geliştirmiş oluyoruz :)
Bilgi için teşekkürler
Giriş aşaması için verimli bir yazı olmuş, teşekkürler.
Makale için teşekkürler.